Human Centered Systems in the Perspective of Organizational and Social Informatics
Rob Kling (acm)
Leigh Star (acm)
Computers and Society, March 1998
If you’re only going to remember one(?) thing:
The question of what is and isn’t HCS may be divided into four parts:
- What do we mean by human?
- What is a system?
- What are the goals of a human-centered system or process?
- What are the processes associated with HCS?’
Human-centered systems are designed to complement human skills. The impetus to build such systems are based on human needs, for information, assistance, or knowledge.
Overview:
The term “human centered automation,” which is one of the intellectual roots of the term “Human Centered Systems,” has been advanced within the field of human factors to refer to system that are
- based on an analysis of the human tasks that the system is aiding
- monitored for performance in terms of human benefits
- built to take account of human skills and
- adaptable easily to changing human needs.
The analysis of any aspect of systems should take into account at least four dimensions of human-centeredness:
- A human centered analysis must take account of varied social units that structure work and information–organizations and teams, communities and their distinctive social processes and practices.
- It would take into account how criteria of evaluation are generated and applied, and for whose benefit. It would include the participation of stakeholder groups
- As with the architecture of buildings, the architecture of machines embody questions of livability, usability and sustainability.
- the question of whose problems are being solved is important–systems which seek only to answer a very narrow technical or economic agenda or a set of theoretical technical points do not belong under the “human centered” rubric.
“One size fits all” seems distinctively non human-centered. On the other hand, we don’t believe that complete tailorability results in human centered systems, because few people have the time or interest to effectively learn how to tailor thousands of features in complex computer systems.
We did not believe that certain kinds of applications, such as medical diagnostic aids, should be automatically be called human-centered because improved medical diagnosis can help people. For example, a medical diagnostic system whose logic is difficult for a doctor to comprehend or interrogate would not be very human-centered.
People adapt and learn, and from the point of view of systems design, development and use, it is important to take account of the adaptational capabilities of humans (Dervin, 1992). Something that freezes at one development stage, or one stereotyped user behavior, will not fit a human centered definition.
What are the processes associated with design, use and analysis of HCS?
understand the importance of multiple media (paper, computing, video, conversation, etc.) in the process of design. That is, information systems are always part of a large ecology of communicative devices and conventions
the usability of a system depends on infrastructural configurations of all sorts. Computers sent to a developing country without knowledge of the problems with its power grid and the dust-filled atmosphere may fail for reasons other than pure design
Technology does not and will not solve social justice problems. For example, putting more computers into inner city classrooms will not per se increase literacy.
articulating the values that are at stake in design processes themselves. This means examining the values of both designers and of the intended systems audiences and also being able to identify value-conflicts.
machinery should not be anthropomorphised. Machines should extend human capability as gracefully as possible.
SAP (information processing system) is not a “human centered system;” it is a strong example of an “organization centered system” that makes exceptional demands upon people to use it effectively. SAP is an interesting contrast to the kinds of Human Centered Systems (and design principles) that a research program should promote.
Neither technical excellence nor market share alone define system survival. ”Network externalities, ” on the other hand, can play a substantial role in the sustainability of system. (Network externalities are the effects on a user of a product or service of others using the same or compatible products or services. Positive network externalities exist if the benefits are an increasing function of the number of other users. Negative network externalities exist if the benefits are a decreasing function of the number of other users.)
The discrepancy between the expected economic benefits of computerization and measured effects has been termed “The Productivity Paradox,” based on a comment attributed to Nobel laureate Robert Solow who remarked that “computers are showing up everywhere except in the [productivity] statistics.” (Not sure this is true. See chart below)
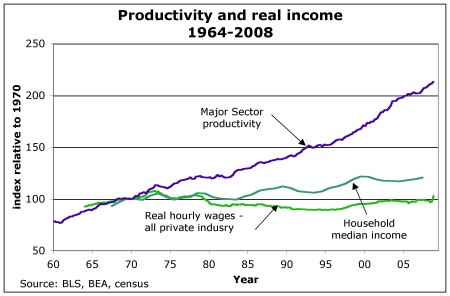
It is common for systems designers to conceptualize computerized systems in terms of organizations and individuals (“users”). But there are important intermediate levels of social organization between individuals and the larger collectivity.
Brown and Duguid (1991) coined the term “communities of practice” (CoPs) to refer to people who are concerned with a common set of work practices. They are not a team, a task force, and not even necessarily an authorized or identified group. What holds them together is a common sense of purpose and a real need to know what each other knows.
Local communities, as well, can be important units of analysis and frames of reference for human centered computing. “Community information systems” may mean organized information provision to special constituencies (e.g. cancer patients, small business owners, hobbyists), or it may be geographically local provision of services, including freenets and other public computing facilities.
email was the “killer application” that drove up the use and demand for the Internet (e.g. in contrast with file transfer)
There is an understanding of emergent social psychological processes when individuals work together in groups with computer networks



